Norwegian Service Centre for Climate Modelling -> SGI optimisation -> Optimising a modified ccm3.2 climate model
Optimising a modified ccm3.2 climate model
By Arild Burud and Egil Støren
Norwegian Service Centre for Climate Modelling
May 2., 2002
Introduction
Jón Egill Kristjánsson (Department of Geophysics, University of Oslo) is using a modified version of the NCAR CCM3 climate model to study the indirect effect of aerosol particles in the atmosphere.The model is parallellized with OpenMP and is implemented on the gridur.ntnu.no computer, typically using 8 processors. The modifications by Kristjánsson have not been optimised for efficient use of the computer, and there could be a potential of reducing the time to run this model.
The NoSerC crew have now investigated the program and made modifications that allow the time-consumption (in CPU-seconds) to be reduced with approximately 25%.
This brief report summarizes the methods and findings in the optimisation process.
Description of changes
Three routines have been modified due to hardcoded directory paths (directories containing datafiles for I/O):chini.F initabc.F data.FOne file has been modified to remove an Y2K-error (causing the year in program output to be shown as 20102 instead of 2002):
getdate.c
Optimised routines
Optimisation of parmix.F
The routine parmix was by itself the most time-consuming routine in the whole program. Several techniques have been utilized to improve speed here.Loops have been modified to bring calculations out of the loops where possible, or even changing loop order to reduce work in the innermost loops. Several loops contained calculation of constant expressions (not dependant of loop increment), which were thus moved outside. One loop involved the calculation of log10(), which was identified to be constant also between each call to parmix. Thus an array was declared in a common block and the necessary values could be precalculated in the initialisation of the model (changes made in const.h, constants.F and koagsub.F).
Parmix also calls the routines intccnb and intccns with several arrays as
arguments. The original version of parmix spent time copying the content of
matrices into temporary arrays before calling intccnb and intccns, afterwards
resulting arrays were copied back to matrices. This process has been changed so
that the routines now work directly on the data in the matrices. See below:
| original | optimised |
|---|---|
do kcomp=1,11 do long=1,nlons lon = ind(long) fraccn(lon,kcomp) = 0. end do end do do kcomp=1,10 do long=1,nlons lon = ind(long) Nnat(lon) = Nnatk(lon,kcomp) Camk(lon)=Cam(lon,kcomp) fbcmk(lon)=fbcm(lon,kcomp) faqmk(lon)=faqm(lon,kcomp) end do call intccnb (nlons, ind, kcomp, relh, Camk, $ Nnat, fbcmk, faqmk, fccn) do long = 1,nlons lon = ind(long) ccn(lon)=ccn(lon)+fccn(lon)*Nnatk(lon,kcomp) fraccn(lon,kcomp) = fccn(lon) end do enddo do kcomp=11,11 call intccns (nlons, ind, kcomp, relh, fccn) do long = 1,nlons lon = ind(long) ccn(lon)=ccn(lon)+fccn(lon)*Nnatk(lon,kcomp) fraccn(lon,kcomp) = fccn(lon) end do enddo |
DO kcomp = 1 , 10
CALL intccnb(Nlons,Ind,kcomp,Relh,
& cam(1,kcomp),Nnatk(1,kcomp),fbcm(1,kcomp),
& faqm(1,kcomp),fraccn(1,kcomp))
ENDDO
kcomp=11
CALL intccns(Nlons,Ind,kcomp,Relh,fraccn(1,kcomp))
|
Optimisation of trcab.F
Loops have been modified to bring calculations out of the loops where possible.
Optimisation of intccnb.F
This routine has been more or less completely rewritten.In the original file there were several loops of the following kind:
do long=1,nlonsand also double loops of the following kind:
lon=ind(long)
...
enddo
do ictot=1,5Initially, the outer and inner loops in the double loops above were interchanged, and then all the the smaller loops (long=1,nlons) were merged into one large loop. This made it no longer neccessary to keep the variables isup1, isup2, ict1, ict2, ifbc1, ifbc2, ifaq1 and ifaq2 as arrays. They were converted to scalars. The loops where these variables were set were also optimised by converting them to 'do while' loops to be able to exit from the loops as soon as the correct values were found.
do long=1,nlons
lon=ind(long)
...
enddo
enddo
Finally, in the last part of the program where arrays f111, f112 etc. are set, parts of the formulaes were found to be the same for several statements. These parts were computed separately, and assigned to new temporary variables.
Optimisation of backgra.F, backgrl.F and backgro.F
These small programs all had a double loop as follows:
do i=1,11
do long=1,nlons
lon = ind(long)
Nnatkl(lon,i)
= basic(i)*(0.5*(pint(lon,lev)+pint(lon,lev+1))/ps0)**vexp
enddo
enddo
The outer and inner loops were interchanged, and the part of the formula
not dependent on i (containing an expensive ** operator)
was computed outside the inner loop and set to a temporary variable.
Removed dangerous use of save
Changes have been made to routines findmcnew.F and moist.F due to dangerous
use of the save statement. In findmcnew.F the following statements
were found:
do long=1,nlons
lon = ind(long)
Nnatkl(lon,i) = basic(i)*(0.5*(pint(lon,lev)+pint(lon,lev+1))/ps0)**vexp
enddo
enddo
real cwo(plond)
save cwo
This array is used for calculations in findmcnew. findmcnew is called within the pcond routine (moist.F) in a loop of two iterations. The intent seems to be that the first time findmcnew is called, cwo is initialized, and the second time, the initialized values are used.
The save statement will force the computer to use the same memory for all parallel processes. If, by co-incidence, two proccesses is active in the findmcnew routine at the same time, we may have the following situation:
proc 1: Initialize cwo (1. iteration)
proc 2: Initialize cwo (1. iteration)
proc 1: Uses cwo (2. iteration) WRONG VALUES !?
The save statement has been removed and the declaration statement (real cwo(plond)) has been moved to the calling routine (pcond) where it will be a local variable. A new dummy argument (cwo) has been added to the findmcnew routine, and the new cwo variable in pcond passed as the actual argument in the findmcnew call.
Math power expressions
Another issue discovered is the use of expressions involving floating point
power (a**3.0). Such expressions can be rewritten to use integer
power (a**3), because the compiler will not inspect floating point
constants to see if they can be changed to integer constants. The resulting
program code is slower with a a**3.0 than with a a**3
type statement, due to differences in the underlying mathematics library.
Even worse is the situation for the specific statement a**2.0,
where a**2 is recognized (and translated) by the compiler as
a*a. When possible, use multiplication instead of power.
A rough timing test was performed on these expressions,
the results are shown below, as a performance ratio:
| expression | expression | performance ratio |
|---|---|---|
| a**2.0 | a**2 | 17:1 |
| a**3.0 | a**3 | 4:1 |
| a**3.0 | a*a*a | 65:1 |
| a**5.0 | a**5 | 3:1 |
| a**5.0 | a*a*a*a*a | 33:1 |
Performance timing
The model has been measured for performance and comparisons are made between three different versions:- ccm3.2: original NCAR model, without Kristjánsson's modifications
- original: Kristjánsson's modified ccm3 model
- optimised: Optimised version of Kristjánsson's modified ccm3 model
time command.
Note that the measured values may vary slightly from one run to another, but the values listed here are considered representative.
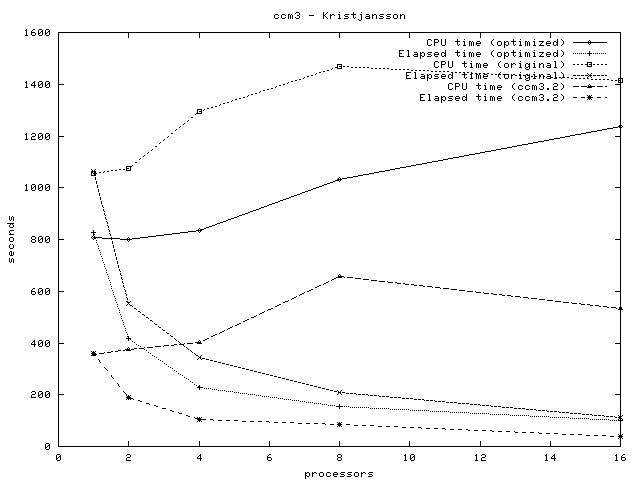
| # processors | CPU time (optimised) | Elapsed time (optimised) | CPU time (original) | Elapsed time (original) | CPU time (ccm3.2) | Elapsed time (ccm3.2) |
|---|---|---|---|---|---|---|
| 1 | 807.9 | 826 | 1055.0 | 1062 | 354.1 | 359 |
| 2 | 798.2 | 416 | 1075.2 | 553 | 373.5 | 190 |
| 4 | 834.4 | 229 | 1295.0 | 345 | 400.4 | 103 |
| 8 | 1032.0 | 153 | 1467.3 | 207 | 655.9 | 86 |
| 16 | 1238.4 | 102 | 1414.8 | 112 | 534.3 | 37 |
Suggestions for further investigations
The work performed so far indicates that there is not much to gain from further optimisation of the fortran code itself. As the program make heavy use of math functions we are investigating the availability of a more optimised library for such functions as pow ("**"),
exp and log.
Another way of parallellization may be considered, as it is seen from our results, the openMP version of ccm3 does not scale well above 8 processors. One may consider use of MPI or other parallellization frameworks to utilize more processors, it is indicated in the ccm3 documentation that the algorithms used are tailored for the use of up to 32 processors.
Finally, the actual version of ccm3 used as basis for this program should be considered
updated to a newer release.
Send comments to webmaster