Norwegian Service Centre for Climate Modelling -> SGI optimisation -> Additional optimization of CCM3.2
Additional optimization of CCM3.2
By Egil Støren and Arild Burud, Norwegian Service Centre for Climate ModellingBackground
The NoSerC team has already optimized a version of the CCM3.2 model based on a source provided by Jon Egill Kristjansson. This is documented in the report Optimising a modified ccm3.2 climate model. Later, new code has been added to the source by Øyvind Seland and Alf Kirkevåg. An integrated version, containing the contributions from all three researchers, has been provided by Øyvind Seland. On July 18. 2002, this source was copied from directory: /home/u4/oyvinds/ccm3.2/SGI.T42.spectral.std.indir on Gridur to our directory, and this source has been the basis for further optimization.Summary of results
All optimization tests have been performed on the Gridur computer.The optimization effort has resulted in an improvement in CPU time for
a 24 hour simulation run using 8 processors, of about 18.5 %.
Summary of optimization methods
A major problem with the code was found to be the use of large arrays and loops scanning whole arrays without much localized reuse of array elements. Also accessing parts of the arrays positioned far apart in the memory inside tight loops, was part of this problem. This use of arrays resulted in poor utilization of the caches. One remedy has been to reorder the array indices for some arrays. One large array has been removed completely from the source, and the declaration of other arrays has been changed (reducing the storage need per array element from 8 bytes to 4 bytes).Another main improvement has resulted from changing the processor scheduling in parallel loops. Two alternatives are available (SIMPLE and DYNAMIC). All loops had, per default, SIMPLE scheduling. For one of the loops, this has been changed to DYNAMIC. This change alone accounted for almost half of the improvement in CPU time.
Additionally, minor improvements have been obtained by various techniques,
such as moving loop-invariant computations out of loops.
Details pertaining to individual files
| opttab.h
initopt.F interpol1.F |
The sequence of the indices in arrays om1, g1, be1 and ke1 has been rearranged to better correspond with the use pattern inside loops. The first index has been moved. It is now the last index. The declaration of these arrays has also been changed from REAL (equivalent to REAL*8) to REAL*4. The constants (found in data files) from which these numbers were computed, did not have the accuracy requiring 8 byte reals. |
| herxin.F
cubxdr.F |
When accessing array elements in these routines, some array indices were itself array values. Since the indices for these array values did not change, they were computed once in the beginning of the routine (preemption technique). |
| pmxsub.F | This file used a large array: dndlk. This array was
used as a huge intermediate storage for values that were computed by a
relatively simple formula. The use of the dndlk array has been
completely abandoned. Everywhere where dndlk array elements have
been used, the original formula has been used instead.
Note: In this process, an inherent bug in the code was encountered which resulted in segmentation error. It was difficult to find the origin of this bug, but the segmentation error could be avoided by keeping parts of the code (including the superfluous declaration of the dndlk array). Some optimization have also been done to this file by moving loop-invariant computations out of loops etc. |
| dyndrv.F
lsmdrv.F scan1ac.F scan2.F sltini.F stepon.F scan1bc.F scanslt.F |
All these files contain loops which are parallelized
using the DOACROSS directive. How this parallelizing is working can be
modified by the MP_SCHEDTYPE clause which may be part of the DOACROSS directive.
By default, scheduling (MP_SCHEDTYPE) is set to SIMPLE, implying a static
distribution of iterations in the loop to all available processors. This
may lead to much work for some processors, while others are idle. An alternative
is to use DYNAMIC scheduling, where iterations are allocated to processors
as soon as they become idle.
By experimenting with these two alternatives for all these files, it
was found that the default SIMPLE alternative was best for all files except
Experiments were also performed to test how DYNAMIC scheduling scales with the number of processors used (see below). All the files have been modified so that all scheduling are now explicitly set. This has only real impact for the scan1bc.F file, where MP_SCHEDTYPE=DYNAMIC is used. For the other files, the default behavior is only made explicit. |
| chinimnd.F
initabc.F |
No optimization was done on these files. Only necessary changes to file path names. |
Experiments with parallel scheduling
To find out how different scheduling options worked out for runs using different number of processors, the following experiment was performed.For all the files using the DOACROSS directive, scheduling was set to either SIMPLE (for all files) or DYNAMIC (for all files). For these two alternatives runs were executed using 2, 4, 8, 12, 16, 20, 24 and 32 processors. Each run was executed three times, and the medians were used to produce the charts below. The first chart shows the CPU time and real time used, measured by the time command. The continuous curve shows the CPU time for an idealized situation where the performance scales perfectly with the number of processors.
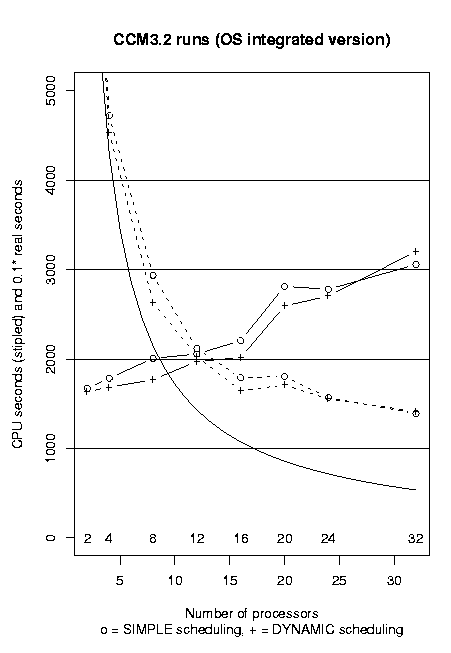
The next chart shows the improvement in CPU performance gained by using DYNAMIC scheduling compared to SIMPLE scheduling.
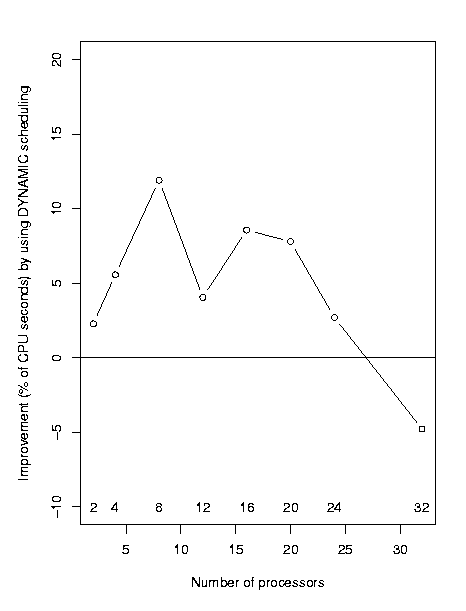
Although this experiment did not take into account that different files
have varying benefits from using the DYNAMIC approach, it shows clearly
that DYNAMIC scheduling is best suited for runs using only up to about
30 processors. Beyond this, use of DYNAMIC scheduling could be counterproductive
due to large overhead time.
Send comments to webmaster